SLAP: Additional Experiments
Experiment Setup
Our team conducted two experiments to evaluate the performance of our SLAP system. Experiment I (SLAP ablations on RLBench tasks) involved training and evaluating five ablated variations of the SLAP's APM system and compare with PerAct's performance on same RLBench taks. Experiment II (SLAP ablations on held-out test set collected from the real-robot) focused on evaluating seven ablated versions of the SLAP's APM system on a held-out test set collected from a real robot. APM ablations and PerAct models in Experiment I share the same training and testing data, which was pre-collected from RLBench and stored in-memory. It is worth noting that the training time required for the PerAct model, as presented in [3], is typically around two weeks. However, our 20-epoch training of the PerAct model resulted in a training time of approximately 45 minutes, which is same as the SLAP training budget. Each model was trained for the same number of steps in order to establish a fair comparison (corresponding to 20 epochs). We provided ground truth interaction points to the ablations where it was applicable.
| Ablation ID | Description |
|---|---|
| A0 | DR: depth noise, positional and rotational randomization as well as color jitter |
| A1 | DR: depth noise, positional and rotational randomization; No color jitter |
| A2 | Without any DR |
| A3 | Interaction hotspot is provided, without any cropping of PCD; No DR |
| A4 | No interaction hotspots, without any cropping of PCD; No DR |
Experiment I Results: Ablations and PerAct on RLBench

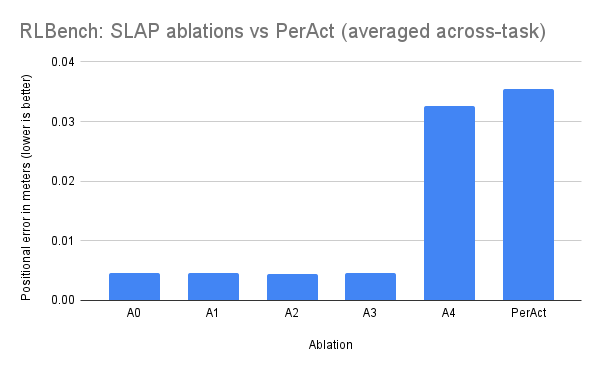
Ablation A0 through A3 behave similarly on simulation data, however not providing the interaction hotspot leads to a significant degradation in performance of the action prediction module (APM). In Fig. 1., we observe that PerAct generally does better than our worse ablation, yet worse than our other models. Due to high positional error on one task, it averages to be closer to the overall error of our worse model in Fig. 2.
Experiment II: Real-world Data
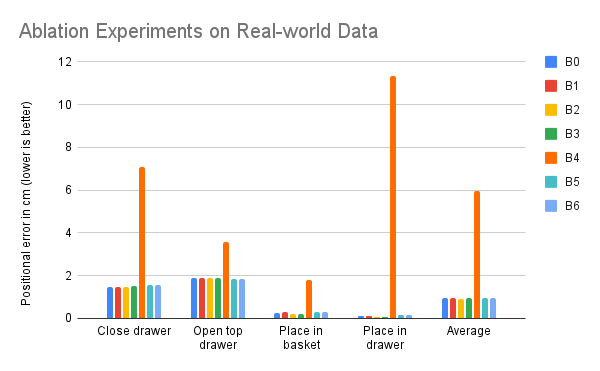
This experiment studies the correlation of ablation performance seen in simulation with performance on real-world data. The real-world data has a larger variation over position and orientation of the object as well as a lot of clutter from objects on table which are not implicated in the given task. If correlations hold then we should see ablations B0 through B3 to be of similar efficacy on real-world data. The ablations studied in this experiment are defined as follows:
| Ablation ID | Description |
|---|---|
| B0 | (APM as in paper)DR: depth noise, positional and rotational randomization as well as color jitter |
| B1 | DR: depth noise, positional and rotational randomization; No color jitter |
| B2 | Without any DR |
| B3 | Interaction hotspot is provided, without any cropping of PCD; No DR |
| B4 | No interaction hotspots, without any cropping of PCD; No DR |
| B5 | B3 with DR; No color jitter |
| B6 | B3 with DR and color jitter |
We see that the trends noticed in simulation correlate with APM performance in rral-world. Our observations suggest that the primary design choice driving SLAP's performance gains is the division of prediction problem into predicting a reliable interaction point which informs the action pose.
Mobile Manipulator Demonstrations
SLAP running on a mobile manipulator with an egocentric camera. With very few demonstrations, SLAP is able to grasp the bottle.
Pick up bottle - Position 1
Pick up bottle - Position 2