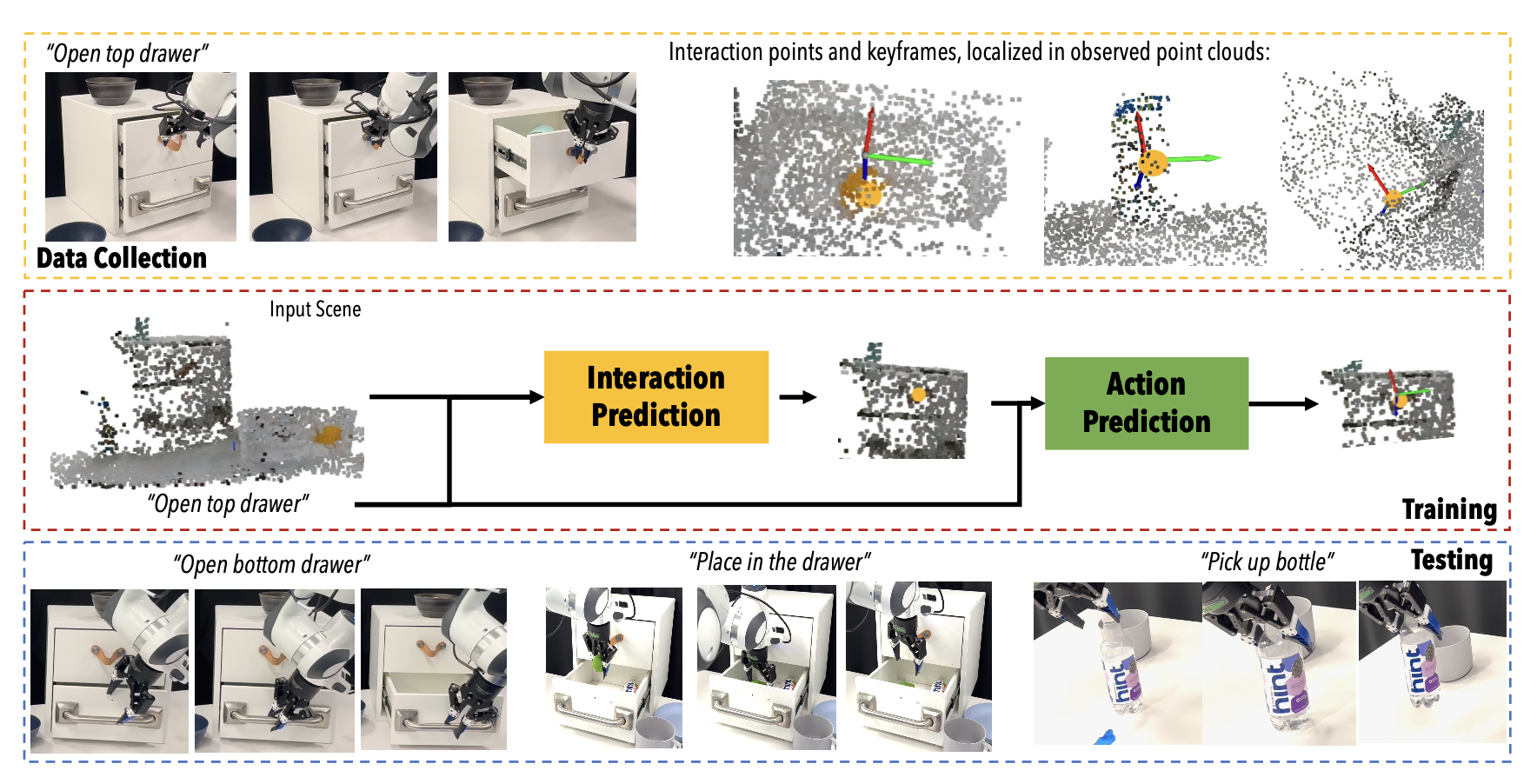
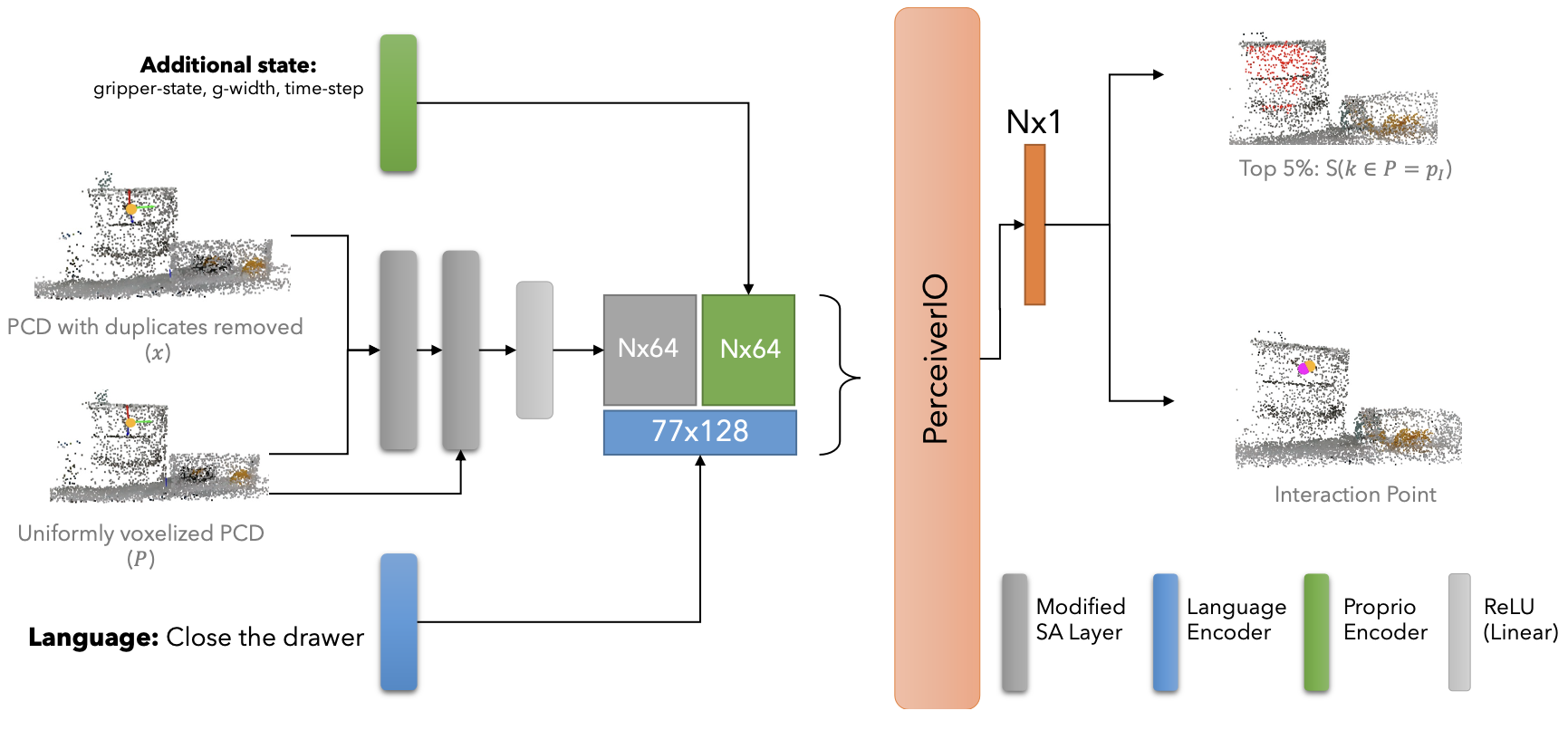
Despite great strides in language-guided manipulation, existing work has been constrained to table-top settings.
Table-tops allow for perfect and consistent camera angles, properties are that do not hold in mobile manipulation. Task
plans that involve moving around the environment must be robust to egocentric views and changes in the plane and angle
of grasp. A further challenge is ensuring this is all true while still being able to learn skills efficiently from
limited data. We propose Spatial-Language Attention Policies (SLAP) as a solution. SLAP uses three-dimensional tokens as
the input representation to train a single multi-task, language-conditioned action prediction policy. Our method shows
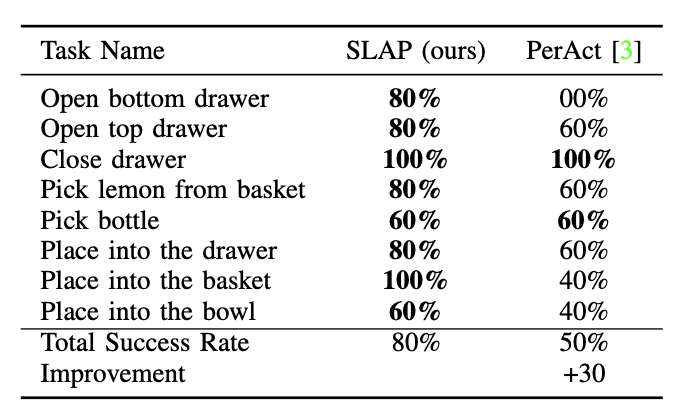
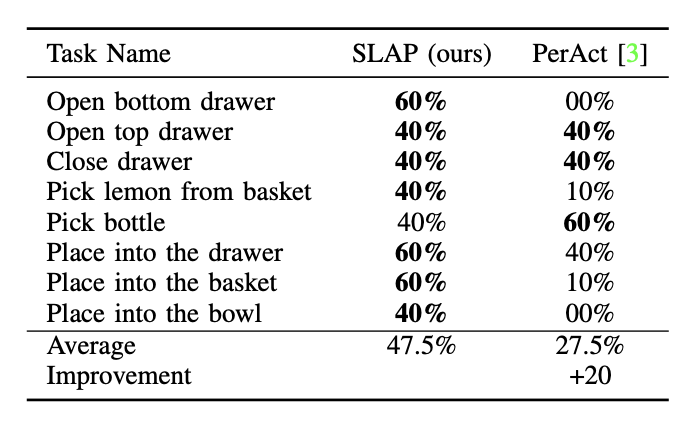
an 80% success rate in the real world across eight tasks with a single model, and a 47.5% success rate when unseen
clutter and unseen object configurations are introduced, even with only a handful of examples per task. This represents
an improvement of 30% over prior work (20% given unseen distractors and configurations). We see a 4x improvement over
baseline in mobile manipulation setting. In addition, we show how SLAPs robustness allows us to execute Task Plans from
open-vocabulary instructions using a large language model for multi-step mobile manipulation.